ニュース
 一覧に戻る
一覧に戻る【イベント出展】SCA/HPCAsia 2026――FLOPSからTTSへ。研究成果を加速するGPUクラウドの新しい評価軸
FLOPSという理論性能ではなく、解が得られるまでの総時間(Time to Solution: TTS)を短縮するITインフラこそが、研究の回転数を増やし、真の研究成果につながる。
2026年1月26日(月)〜29日(木)、アジア最大級のHPC国際会議「SCA/HPCAsia 2026」が大阪府立国際会議場(グランキューブ大阪)にて開催されました。GMOインターネットはダイヤモンドスポンサーとして参加し、「GMO GPUクラウド」のNVIDIA HGX B300搭載サーバーやNAMD・LAMMPSによるベンチマーク結果を展示しました。開催概要に関するレポートはこちら
アカデミア領域のイベントへの初参加となった今回、当社はまず商用GPUクラウドサービス「GMO GPUクラウド」を提供する企業として研究者の方々に認知いただくことを第一目標に掲げました。あわせて、大学・研究機関を中心としたHPC/AIユーザーの皆さまに向け、「GPUクラウドの価値は計算機性能(FLOPS)ではなく、研究成果に直結する”時間(Time to Solution: TTS)”の短縮にある」というメッセージを発信しました。
会期中は、研究現場で日常的に生じる「リソース順番待ち」「IT環境制約」「前後処理の手戻り」といった研究スピードを妨げる要因を起点に対話を重ね、TTSを軸にしたアプローチに対して多くのポジティブな反応を得ました。本レポートでは、その内容をお伝えします。
【なぜ今、TTSなのか】
~”速い計算機”より”早く答えに辿り着く環境”を~
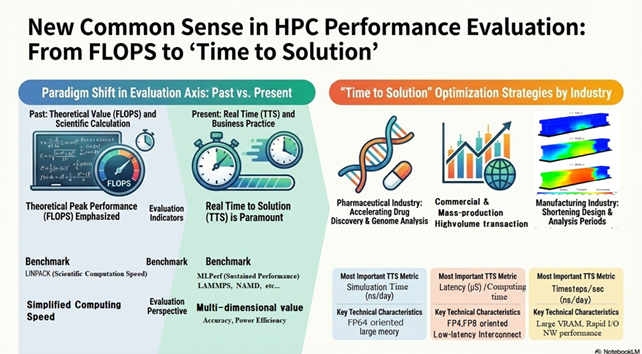
HPCの議論はピーク性能(FLOPS)にフォーカスされがちですが、実際の研究現場ではジョブ待ち時間・I/O・前後処理・環境差分などが積み重なり、「計算機の理論性能が速い=研究が速い」とは限りません。当社は、GPUクラウドの意義を「研究の回転数(試行回数)を増やすこと」として整理し、TTS短縮こそが研究成果を押し上げるという観点でメッセージを構成しました。
~研究者の“待ち時間”を、成果創出の阻害要因として扱う~
ブースでは、スペック比較ではなく「結果が出るまでに何日待っているか」「その間に何回の仮説検証が止まっているか」を起点に研究者の方々と対話しました。
~FLOPS→TTSへのパラダイムシフト~
本展示の中心テーマは、HPC評価軸を「技術的な凄さの証明」から「成果に至るまでの実効時間(TTS)」へ翻訳することだった。TTSは、計算時間だけでなく、待ち時間・データ転送・後処理も含めた“解が出るまでの総時間”として捉え、研究における本質的なKPIとして提示した。
~分野別ベンチマーク:NAMD・LAMMPSが示すTTSの個別性~
TTSの重要性と研究テーマことの個別性を実感してもらうために、代表的な研究エリアのキーになるベンチマーク指標として、分子動力学シミュレーションツールとしてのNAMD、材料科学でよくつかわれるシミュレーションツールとしてのLAMMPSといった、研究分野別ツールでのベンチマーク実測値を提示して、従来のHPC FLOPS一本やりの研究環境との差異を実感してもらえる構成とした。
また最近、ビジネスの様々な局面で多用されている大規模言語モデル(LLM)の性能指標としてのMLPerfが商用エリアでの大量業務処理効率化のAIの性能指標としてとして機能しており、アカデミアとビジネスをつなぐ共通言語として説明した。
【 GPU”適材適所”:TTS最適化のためのラインナップ構成】
今回、弊社が2025年12月に国内最速で商用提供をはじめた「NVIDIA Blackwell Ultra GPU」を搭載した最新機種「NVIDIA HGX B300」の会場展示を行い、多くの注目を集めた。研究においてTTSを目指すということは、その最新機種一択にこだわるのではなく、 弊社サービスですでに提供してきた主軸のサービスインフラとしてのNVIDIA H200 Tensor コアGPU搭載のクラウドサービス(以下、H200) (B300と比較してFP64,32Oriented) や,さらに計算速度よりコストパフォーマンスをより重視するケースの検討候補として挙がりうる、「NVIDIA H100 Tensor コア GPU (以下、NVIDIA H100)」や「NVIDIA L4 Tensor コア GPU (以下、NVIDIA L4)も、各研究エリアのTTS短縮実現のために、弊社サービスラインナップとして揃えており、各研究領域のTTS最適化に合わせた構成を提案している。
【まずは”実データでTTSを測る”PoCから始めましょう】
理論値の比較よりも、実運用でのTTSがどれだけ縮むかを確認することを優先し、以下3ステップのPoC進行をご提案しています。SCA/HPCAsiaのブースでも、この流れでのご相談を推奨しました。
- 現状のTTSボトルネック把握(待ち時間・I/O・VRAM・並列効率など)
- 実データ・実コードによるPoC(同条件での比較検証)
- 効果が出るインフラ構成のテンプレート化(研究サイクルの継続的高速化)
【おわりに】
SCA/HPCAsiaを通じて、GMOインターネットはGPUクラウドサービスを提供する企業としてアカデミア領域への認知を広げるとともに、「GPUクラウドの価値=研究成果までの時間(TTS)を短縮すること」というメッセージを明確に打ち出しました。研究現場の実感に根ざしたインフラ要件の議論に参入し、多くのポジティブな反応を得られたことは大きな成果でした。
当日ご来場いただけなかった方も、「TTS(研究成果までの時間)」の観点で現状に課題をお感じであれば、貴組織のワークロードに合わせた実データPoCからご相談を承ります。
▼詳しくは下記からお問い合わせください
関連記事
お問い合わせ
お問い合わせフォームにご入力いただき、送信ボタンをクリックしてください。
弊社担当からご入力いただいたメールアドレス宛にご連絡いたします。
