ニュース
 一覧に戻る
一覧に戻る
GMO GPUクラウドで最新推論OSS『NVIDIA Dynamo』を動かしてみた
~Dynamo Serve による Inference Grapsh のデプロイを試す(Vol.2)~

皆さんこんにちは:-)
GMOインターネットでGPUクラウドの開発・普及活動をしている大川です。
前回、NVIDIA GTC2025 の参加レポートとともに「NVIDIA Dynamo」を GMO GPUクラウド上で動かしてみるという記事をお届けし、Dynamo の最も基本的な機能である「Dynamo Run」によるローカル推論を試しました。
しかしながら、Dynamo の目指すところはオーケストレーション含む推論プラットフォームを構築することにありますので、今回はもう少し踏み込んだ機能、具体的には Inferenece Graph のデプロイを試してみたいと思います。
Inference Graph とは?
Inference Graph とは、LLM 推論を処理する複数コンポーネントサービスの総称です。具体的には、以前も触れたとおり「フロントエンド」「プロセッサ」「ルーター」「ワーカー」といったサービスから構成され、Dynamo SDK に則って各サービスを実装・カスタムすることもできます。
また、Inference Graph の展開には nats/etcd/grafana/prometheus といった関連サービスのデプロイが前提となっており、メトリックなどを参照できるように設計されています。
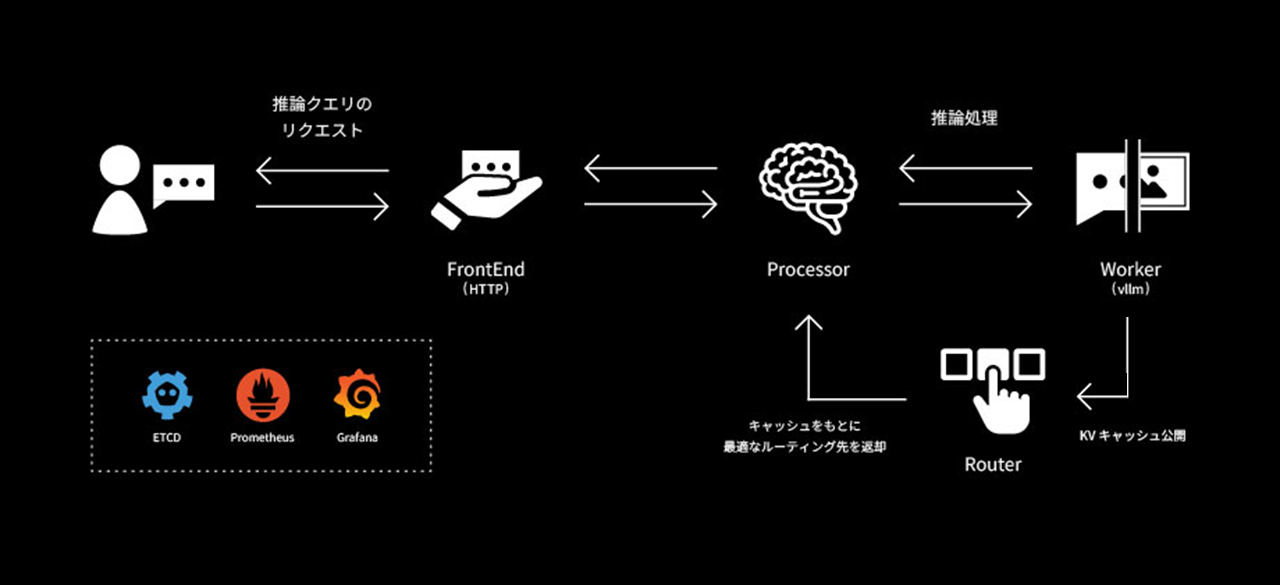
Inferenece Graph を定義したら、Dynamo Serve(dynamo serve コマンド)を使用してそれらをローカル環境にデプロイします。
これにより、前述のコンポーネントがローカル環境に展開されますので、フロントエンドを経由したローカル推論が実行できるようになります。
$ dynamo serve <Graph Definition>:Frontend -f /path/to/<config>.yamlgithub には Dynamo Serve を用いた Inferenece Graph の Example が公開されていますので、GMO GPUクラウド(以下、GPUクラウド)上で試してみたいと思います。
※注意※
なお、GPUクラウドではコンテナ実行環境としてSingularityを採用しているため、DockerやHelmをそのまま利用することができません。後続の手順では各プログラム類をGPUクラウド向けに変換して動作させていますので予めご了承ください。
関連コンポーネントのデプロイ
まずは Inference Graph の前提となる etcd などのコンポーネントをデプロイしていきます。
github には展開用の Composeファイル が提供されていますが、前述の通り GPUクラウドでは Docker がそのまま動作しませんので、工夫が必要です。
まずはそれぞれの Docker コンテナを Singularity コンテナ(.sif ファイル)へ変換します
$ mkdir $HOME/dynamo-test && cd $HOME/dynamo-test
$ srun -p part-cpu singularity pull docker://nats
$ srun -p part-cpu singularity pull docker://bitnami/etcd
$ srun -p part-cpu singularity pull docker://prom/prometheus:latest
$ srun -p part-cpu singularity pull docker://grafana/grafana-enterprise:latest その後、Docker Compose の Composeファイル に従ってそれぞれのコンテナを Singularity 向けに書き換えます。
・run_nats.sh
#!/bin/bash
#SBATCH -p part-group_xxxxxx
#SBATCH -w aic-gh2x-xxxxxx
#SBATCH --job-name nats-server
#SBATCH --output logs/nats/%x-%j.log
#SBATCH --error logs/nats/%x-%j.err
module load singularitypro
singularity exec images/nats_latest.sif nats-server -js --trace ・run_etcd.sh
#!/bin/bash
#SBATCH -p part-group_xxxxxx
#SBATCH -w aic-gh2x-xxxxxx
#SBATCH --job-name etcd-server
#SBATCH --output logs/etcd/%x-%j.log
#SBATCH --error logs/etcd/%x-%j.err
module load singularitypro
singularity exec \
--env ALLOW_NONE_AUTHENTICATION=yes \
images/etcd_latest.sif \
etcd ・run_prometheus.sh
#!/bin/bash
#SBATCH -p part-group_xxxxxx
#SBATCH -w aic-gh2x-xxxxxx
#SBATCH --job-name prometheus
#SBATCH --output logs/prometheus/%x-%j.log
#SBATCH --error logs/prometheus/%x-%j.err
# Ref: https://github.com/ai-dynamo/dynamo/blob/main/deploy/metrics
export PROMETHEUS_CONFIG=$HOME/dynamo-test/config/prometheus.yml
export PROMETHEUS_DIR=$HOME/dynamo-test/mount/prometheus
module load singularitypro
singularity exec --bind $PROMETHEUS_DIR:/prometheus \
images/prometheus_latest.sif \
prometheus \
--config.file=$PROMETHEUS_CONFIG \
--storage.tsdb.path=/prometheus \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.console.templates=/etc/prometheus/consoles \
--web.enable-lifecycle ・run_grafana.sh
#!/bin/bash
#SBATCH -p part-group_xxxxxx
#SBATCH -w aic-gh2x-xxxxxx
#SBATCH --job-name grafana
#SBATCH --output logs/grafana/%x-%j.log
#SBATCH --error logs/grafana/%x-%j.err
# Ref: https://github.com/ai-dynamo/dynamo/blob/main/deploy/metrics
export GRAFANA_DASHBOARDS_CONFIG=$HOME/dynamo-test/metrics/dashboards
export GRAFANA_DATASOURCE_CONFIG=$HOME/dynamo-test/metrics/datasources
export GRAFANA_DIR=$HOME/dynamo-test/mount/grafana
module load singularitypro
singularity exec \
--bind $GRAFANA_DASHBOARDS_CONFIG:/etc/grafana/provisioning/dashboards \
--bind $GRAFANA_DATASOURCE_CONFIG:/etc/grafana/provisioning/datasources \
--bind $GRAFANA_DIR:/var/lib/grafana \
--env GF_SERVER_HTTP_PORT=3001 \
--env GF_SECURITY_ADMIN_USER=admin \
--env GF_SECURITY_ADMIN_PASSWORD=admin \
--env GF_USERS_ALLOW_SIGN_UP=false \
--env GF_INSTALL_PLUGINS=grafana-piechart-panel \
--env GF_DASHBOARDS_MIN_REFRESH_INTERVAL=2s \
images/grafana-enterprise_latest.sif \
grafana server \
--homepath /usr/share/grafana これらのコンテナをそれぞれ Slurm のジョブとして起動します。
$ sbatch run_etcd.sh
$ sbatch run_nats.sh
$ sbatch run_prometheus.sh
$ sbatch run_grafana.sh これにより、当該ノード上で必要なコンポーネントを動作させることができました。
Dynamo Serve による Inferenece Graph のデプロイ
それでは Dynamo Serve を使用して Example の Inferenece Graph をデプロイしてみます。
まずは Example のプログラム類を任意のディレクトリへコピーし、前回の記事で作成した Dynamo 用コンテナ(dynamo.sif)も配置します。
$ git clone https://github.com/ai-dynamo/dynamo.git
...
$ mkdir $HOME/llm && cd $HOME/llm
$ cp –R $HOME/dynamo/examples/llm .
$ cp /path/to/dynamo.sif . 続けて、Slurm ジョブ起動用のシェルスクリプトを書きます。
デプロイに必要な configs/agg.yaml は上記 github で提供されているもので、「フロントエンド」「プロセッサ」「ワーカー」のデプロイが含まれています。
・run_dynamo.sh
#!/bin/bash
#SBATCH -p part-group_xxxxxx
#SBATCH -w aic-gh2x-xxxxxx
#SBATCH --job-name dynamo
#SBATCH --output logs/dynamo/%x-%j.log
#SBATCH --error logs/dynamo/%x-%j.err
module load singularitypro
singularity exec --nv dynamo.sif \
dynamo serve graphs.agg:Frontend -f configs/agg.yaml ※デフォルトで指定されているモデルは Hugging Face の deepseek-ai/DeepSeek-R1-Distill-Llama-8B です。
なお、過去の推論リクエストの処理をメモリに保持する KV キャッシュ機能を有効にする場合は「ルーター」が必要で、その場合は configs/agg_router.yaml を指定し、グラフ定義もそれに準じたものに変更します。今回は最小構成なので、こちらは使用していません。
最後に作成したシェルスクリプトを Slurm ジョブとして起動し、Dynamo Serve によるデプロイを開始します。GPU 枚数に制限はかけていないので 1 ノード分の GPU(H200x8)が利用可能です。
$ sbatch run_dynamo.sh
$ tail –f logs/dynamo/dynamo-xxxxxx.log
...
INFO 04-07 16:43:26 cuda.py:230] Using Flash Attention backend.
INFO 04-07 16:43:27 model_runner.py:1110] Starting to load model deepseek-ai/DeepSeek-R1-Distill-Llama-8B...
INFO 04-07 16:43:29 weight_utils.py:252] Using model weights format ['*.safetensors']
INFO 04-07 16:43:41 model_runner.py:1115] Loading model weights took 14.9888 GB
INFO 04-07 16:43:43 worker.py:269] Memory profiling takes 1.66 seconds
INFO 04-07 16:43:43 worker.py:269] the current vLLM instance can use total_gpu_memory (139.72GiB) x gpu_memory_utilization (0.90) = 125.75GiB
INFO 04-07 16:43:43 worker.py:269] model weights take 14.99GiB; non_torch_memory takes 0.15GiB; PyTorch activation peak memory takes 1.72GiB; the rest of the memory reserved for KV Cache is 108.89GiB. INFO 04-07 16:43:43 executor_base.py:110] # CUDA blocks: 13937, # CPU blocks: 512
INFO 04-07 16:43:43 executor_base.py:115] Maximum concurrency for 16384 tokens per request: 54.44x
INFO 04-07 16:43:44 llm_engine.py:477] init engine (profile, create kv cache, warmup model) took 3.33 seconds Inferenece Graph の展開が完了したら、フロントエンドにサンプルのリクエストを投げてみます。
$ vim data.json
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"messages": [
{
"role": "user",
"content": "GMOインターネットについて日本語で教えてください。"
}
],
"stream":false,
"max_tokens": 300
}
$ curl -s -H "Content-Type: application/json" \
> -d @./data.json \
> aic-gh2x-xxxxxx:pppp/v1/chat/completions | \
> jq .choices[].message.content
"まず、GMOインターネットの概要を説明します。GMOインターネットは、国内外の通信回線を活用して、高品質なネットサービスの提供を謟じている企業です。繰り返し盆地 Engineer を経て ... snip きちんと応答が得られました!
#日本語での追加学習を行ったモデルではないと思うので、日本語の精度は微妙ですね 🙁
今回は少し工夫を凝らしたものの、GPUクラウド上で Inference Graph を展開しましたが、いかがでしたでしょうか。
ここまで試してみると、やはりオーケストレーション(= マルチノード)や性能という面での動作が気になるところです。今後より詳しい機能について深堀していきますので乞うご期待ください!
■ GMO GPUクラウドについて
GMO GPUクラウド(https://gpucloud.gmo/)は、NVIDIA H200 GPU や NVIDIA Spectrum-X を搭載した、国内最速クラスの高性能GPUクラウドサービスです。生成AIや機械学習、HPC向けに最適化された構成となっており、研究・開発の効率化とコスト最適化を実現します。
また、SlurmやSingularityなど、業界標準のツールにも対応しており、先進的なAIワークロードをシームレスに実行できる環境を提供します。
【6月30日まで!】無料トライアルキャンペーン実施中!!
本記事の内容は、NVIDIA GTC 2025で発表された「Dynamo」をGMO GPUクラウド上で実行した結果を基に記載しております。動作環境や設定によって結果が異なる可能性があり、すべての環境での動作を保証するものではありません。正式な仕様やサポートについては、各ソフトウェア・サービスの公式情報をご確認ください。
関連記事
お問い合わせ
お問い合わせフォームにご入力いただき、送信ボタンをクリックしてください。
弊社担当からご入力いただいたメールアドレス宛にご連絡いたします。
