ニュース
 一覧に戻る
一覧に戻る【「GMO GPUクラウド」で生成AIの学習・チューニング・推論を実行~株式会社マクニカ】

 検証内容
検証内容2025年1月28日(火)、NVIDIA社・DELL社・CTC社・GMOインターネットの4社共催による特別招待制AIセミナーでの講演内容をダイジェストでお伝えします。
株式会社マクニカ クラビス カンパニー部長 北島 佑樹氏が、『GMO GPUクラウド上で実装する生成AIアプリケーション』 ~最新モデルを使った合成データ生成からFine-Tuningにおけるケーススタディ紹介~と題して講演を行いました。
検証内容
半導体とネットワークセキュリティの専門商社であるマクニカは、NVIDIAの代理店としてAIの社会実装をサポート。NVIDIAのハードウェア・ソフトウェアのポートフォリオを顧客に提供し、推論から学習までのトータルソリューションを展開しています。データセンター向けGPUクラスタの導入支援にも力を入れていますが、顧客向けの検証環境で使用しているのはNVIDIA🄬 H100 GPUであるため、
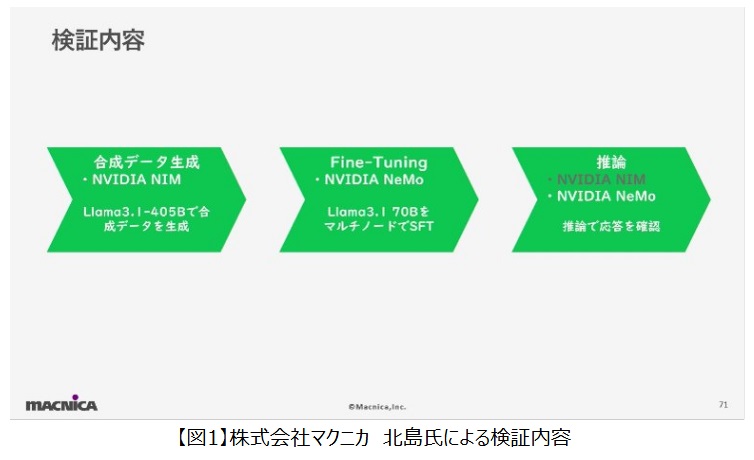
NVIDIA H200を搭載した「GMO GPUクラウド」上で、生成AIアプリケーションを動かす検証を実施。
NVIDIAが提供する生成AIモデルなどのソフトウェアスタックを活用して、
- 合成データ生成: NVIDIA NIM™ (Model : Llama3.1-405B-instruct)で、405B(4050億パラメーター)
- Fine-Tuning:NVIDIA NeMo™ (Model : Llama-3.1-Swallow-70B)
- 推論デプロイ: NVIDIA NeMo (TensorRT-LLM + Triton Inference Server)
の3要素から構成された生成AI開発パイプラインを「GMO GPUクラウド」の「NVIDIA H200 TensorコアGPU」4ノード(H200×8基×4)で実行したことが紹介されました[図1]。
検証結果とパフォーマンス
「合成データ生成」については、4,050億パラメーターという大きな合成データ生成モデルを使用してNIMコンテナをデプロイし、Q&Aがペアになった合成データを生成。北島氏によると、これほどの大きなモデルを「GMO GPUクラウド」4ノードのうち1ノードのみで動かしていたとのことで、NVIDIA H200の大容量メモリの効果を実証できたのが大きな成果だと強調。
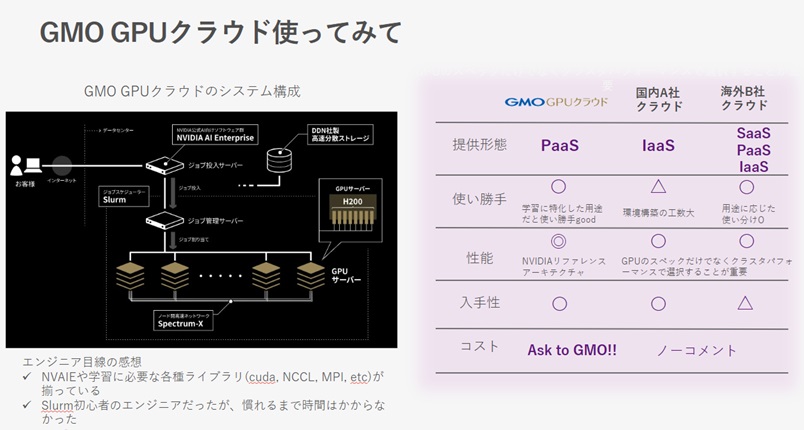
「Fine-Tuning」と「推論デプロイ」については、マルチノードでノード間の通信が頻繁に発生する環境でも、NeMoフレームワークによる機械学習を容易に実行。また、2ノード使用と4ノード使用とで実行時間を比較したところ、4ノード使用の方が約40%の実行時間が削減を確認。最後に、北島氏はエンジニア目線での「GMO GPUクラウド」を使用した感想を紹介。他社クラウドとの比較を交えつつ、ジョブスケジューラ(Slurm)により効率化されたインフラ環境で複数のジョブを並行して検証できる点、現時点において国内唯一となるNVIDIA推奨環境であるNVIDIA Spectrum™-Xが利用できる点を評価するコメントが述べられました。
関連記事
お問い合わせ
お問い合わせフォームにご入力いただき、送信ボタンをクリックしてください。
弊社担当からご入力いただいたメールアドレス宛にご連絡いたします。
